Theory - Apache Spark
Apache Spark is an open source, Hadoop-compatible, fast and expressive cluster-computing platform.
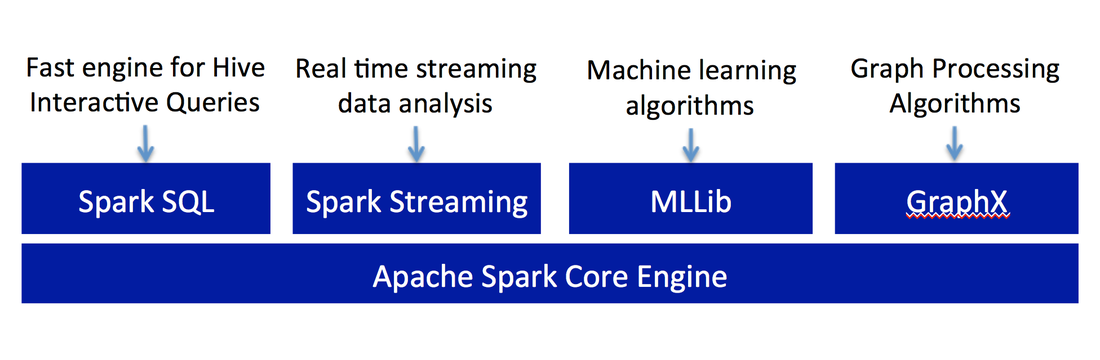
Apache Spark Stack
Major Advantages of Apache Spark -
- Lightning speed of computation because data are loaded in distributed memory (RAM) over a cluster of machines.
- Highly accessible through standard APIs built in Java, Scala, Python, SQL (for interactive queries) and has rich set of machine learning libraries available out of the box.
- Compatibility with existing Hadoop v1 (SIMR) and 2.x (YARN) ecosystems so companies can leverage their existing infrastructure.
- Convenient download and installation processes. Convenient shell (REPL: Read-Eval-Print-Loop) to interactively learn the APIs.
- Enhanced productivity due to high level constructs that keep the focus on content of computation
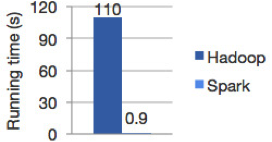
Difference between Apache Hadoop and Apache Spark
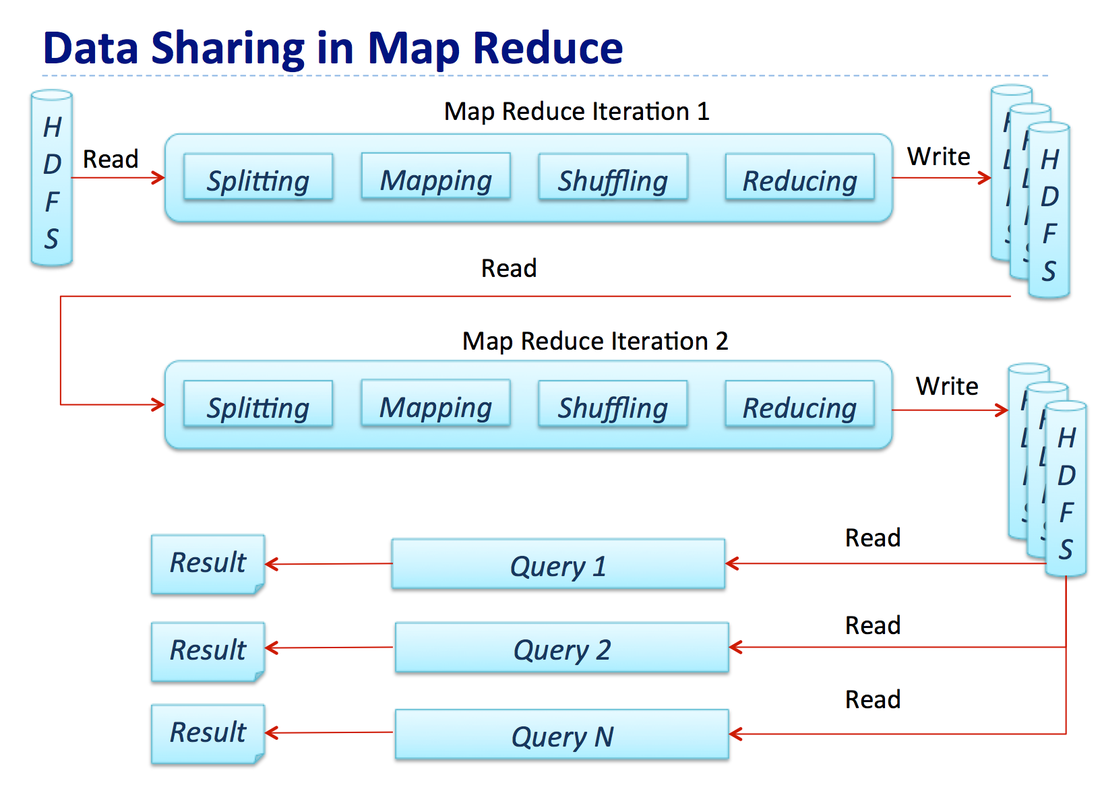
How job process in Apache Hadoop (Map Reduce Job) -
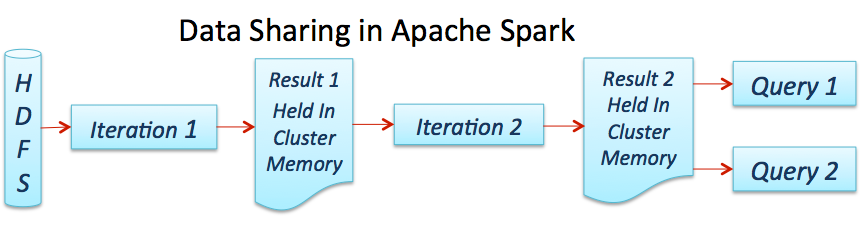
How Job Process in Apache Spark
What is Resilient Data Set
- It is a core concept of Apache Spark.
- It is an immutable distributed collection of data, which is partitioned across machines in a cluster.
- It facilitates two types of operations:
- Transformation
- Action
- A transformation is an operation such as filter(), map(), or union() on an RDD that yields another RDD.
- An action is an operation such as count(), first(), take(n), or collect() that triggers a computation, returns a value back to the Master, or writes to a stable storage system.
- Transformations are lazily evaluated, in that they don’t run until an action warrants it.
- Spark Master/Driver remembers the transformations applied to an RDD, so if a partition is lost (say a slave machine goes down), that partition can easily be reconstructed on some other machine in the cluster. That is why is it called “Resilient.”
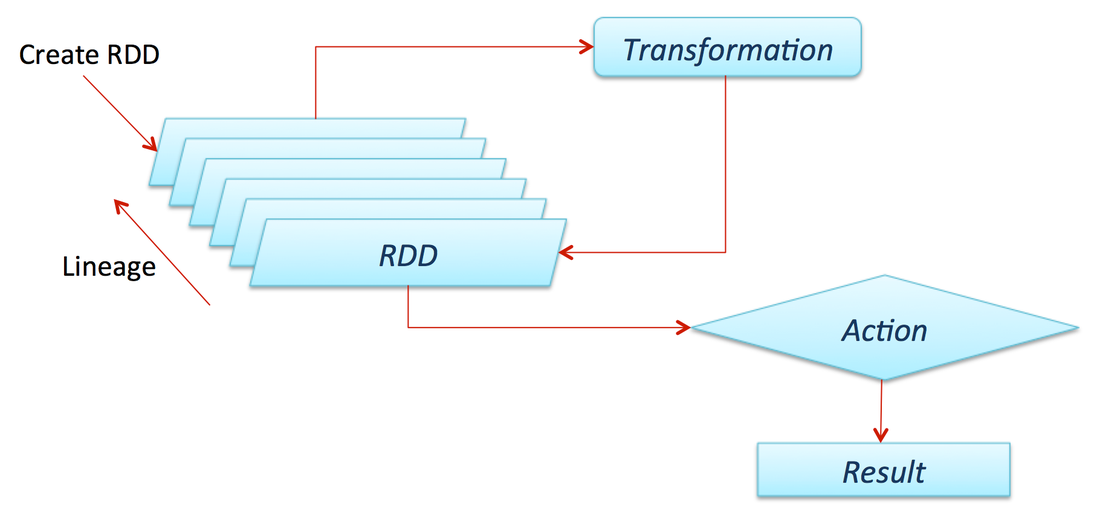
how transformations are lazily evaluated
Word Count Example
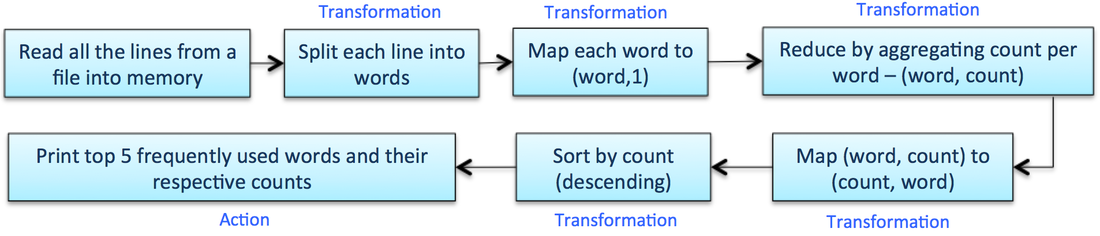
Reference Website : http://refcardz.dzone.com/refcardz/apache-spark#refcard-download-social-buttons-display
Thank You :)
Anshul Shrivastava
Thank You :)
Anshul Shrivastava
